
Já se perguntou como seria possível prever o vencedor de um grande torneio de tênis como Wimbledon ou o Australian Open? No universo onde esporte e tecnologia se encontram, algoritmos de machine learning estão revolucionando a forma como analisamos resultados esportivos. Neste artigo, vamos mergulhar no fascinante mundo da previsão de resultados no tênis usando Random Forest e outros algoritmos avançados, uma abordagem que combina estatística, programação e paixão pelo esporte.
Entendendo a Base: Decision Trees e Random Forest
💡 Dica: Pra testar ChatGPT em português sem cadastro, abra a demo grátis em /talk.php — 5 mensagens em GPT-4o-mini, sem cartão.
Antes de entrarmos nos detalhes das previsões de tênis, é importante compreender como funcionam os algoritmos que tornam isso possível. As Árvores de Decisão (Decision Trees) são a base do nosso modelo preditivo, funcionando de maneira surpreendentemente intuitiva.
O que é uma Árvore de Decisão?
Uma Árvore de Decisão é como um livro de “escolha sua própria aventura”, mas em vez de decidir se você vai enfrentar um dragão ou fugir, ela decide quem vencerá uma partida de tênis. O algoritmo faz uma série de perguntas simples de “sim ou não” para classificar os dados.
Para exemplificar, vamos usar um caso clássico: o desastre do Titanic. Uma Árvore de Decisão analisando a sobrevivência dos passageiros poderia perguntar:
- O passageiro pagou mais de $20 pelo bilhete?
- Estava na primeira classe?
- Era do sexo feminino?
Cada resposta direciona para um novo nó da árvore, até chegarmos a uma previsão final. O mais interessante é que este algoritmo não requer cálculos complexos, apenas lógica simples e aritmética básica.
Evoluindo para Random Forest
Uma única Árvore de Decisão tende a ser sensível aos dados específicos com os quais foi treinada, o que chamamos de alta variância. É aí que entra o Random Forest, um modelo que cria múltiplas árvores, cada uma fazendo sua própria previsão, e combina os resultados através de votação majoritária.
O segredo para construir um Random Forest eficiente está em gerar várias árvores usando:
- Diferentes subconjuntos aleatórios dos dados
- Diferentes subconjuntos de variáveis
Essa abordagem torna o modelo mais robusto e preciso, reduzindo o risco de overfitting (quando o modelo “decora” os dados de treinamento, mas falha com novos dados).
A Busca por Dados de Qualidade no Tênis
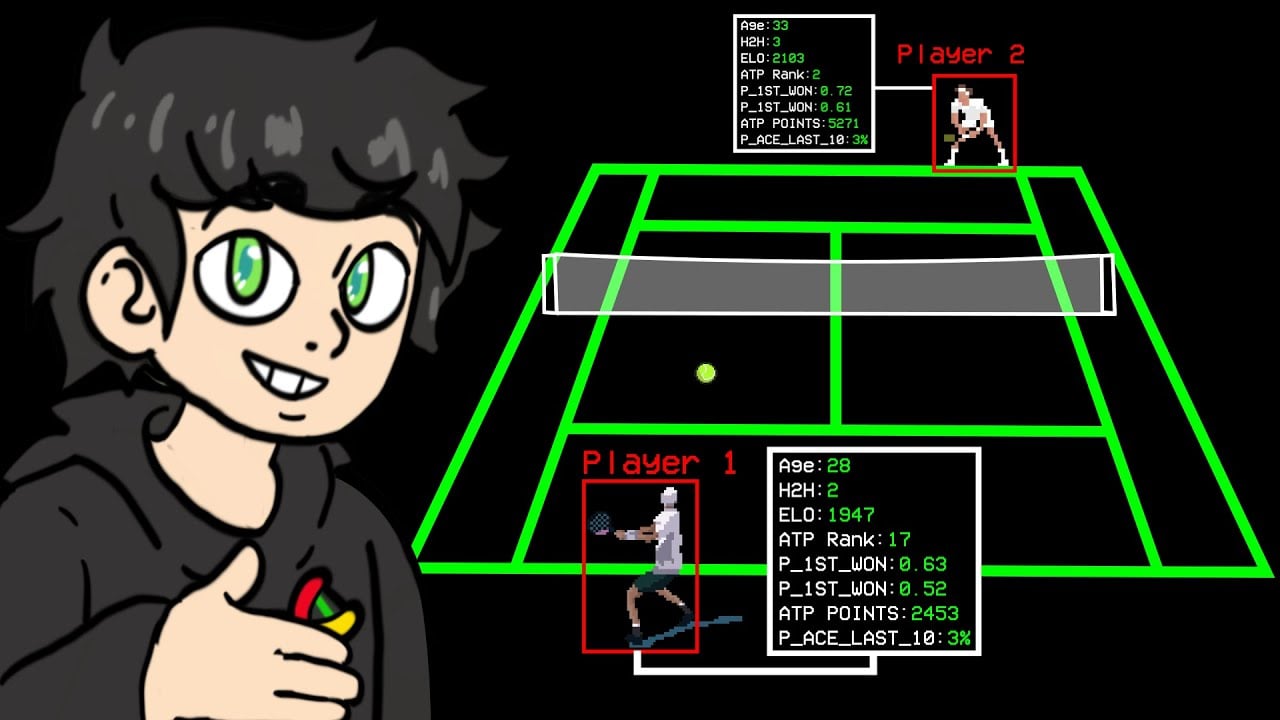
Para construir um modelo preditivo eficiente, precisamos de dados. Não apenas alguns dados, mas muitos dados detalhados. No caso do tênis, isso significa:
- Break points
- Duplas faltas
- Estatísticas de forehand e backhand
- Informações físicas dos jogadores (altura, idade)
- Histórico de partidas
Para este estudo, foi utilizado um conjunto de dados extraordinário: todas as partidas da ATP (Associação de Tenistas Profissionais) de 1981 a 2024. Esse tesouro estatístico inclui desde a histórica final de Wimbledon de 2008 entre Rafael Nadal e Roger Federer, até os confrontos mais recentes entre as novas estrelas do esporte.
Preparando os Dados para Análise
Antes de alimentar um algoritmo de machine learning, é necessário preparar os dados. Este processo inclui:
- Combinar diferentes conjuntos de dados
- Remover dados incompletos
- Calcular a diferença de ranking entre vencedor e perdedor
- Preparar estatísticas relevantes como:
Entre essas estatísticas, destacou-se o Sistema ELO, uma métrica originalmente usada no xadrez e adaptada para o tênis. O ELO é uma forma de aproximar o nível de habilidade de um jogador, começando em torno de 1.500 pontos (média) e evoluindo conforme o desempenho em partidas.
O Sistema ELO Aplicado ao Tênis
O sistema ELO provou ser particularmente valioso na previsão de resultados de tênis. Vejamos como funciona:
Como o ELO Evolui com o Tempo
Tomando Roger Federer como exemplo, no início de sua carreira, seu rating ELO estava em torno de 1.500. Conforme foi vencendo partidas, sua pontuação disparou, eventualmente consolidando-o como um dos maiores jogadores de todos os tempos.
O cálculo do ELO é relativamente simples. Por exemplo, na final de Wimbledon de 2023 entre Carlos Alcaraz e Novak Djokovic, seus ratings eram aproximadamente 2.063 e 2.120, respectivamente. Quando Alcaraz venceu a partida, seu rating aumentou cerca de 14 pontos, enquanto Djokovic perdeu aproximadamente a mesma quantidade.
ELO Específico por Superfície
Uma inovação importante no modelo foi a implementação do ELO específico por superfície. No tênis, o desempenho varia significativamente dependendo se o jogo é em quadra de saibro, grama ou piso duro.
Rafael Nadal, conhecido como “Rei do Saibro”, tem um ELO impressionante nessa superfície, refletindo seu domínio no French Open (14 títulos, com 112 vitórias e apenas 4 derrotas). Similarmente, outros jogadores têm preferências por superfícies específicas, que são capturadas por esta métrica.
Resultados e Desempenho dos Modelos
Após treinar diversos modelos com os dados de tênis, obtivemos resultados fascinantes:
- Árvore de Decisão única: 74% de precisão
- Previsão baseada apenas no ELO: 72% de precisão
- Random Forest: 76% de precisão
- XGBoost: 85% de precisão (o melhor desempenho!)
- Rede Neural: 83% de precisão
O XGBoost, uma versão aprimorada do Random Forest que utiliza boosting e regularização para prevenir overfitting, destacou-se como o modelo mais eficiente.
Testando o Modelo no Australian Open
Para verificar a eficácia real do modelo, foi realizado um teste com o Australian Open de 2024, um torneio não incluído nos dados de treinamento. Os resultados foram impressionantes:
- O modelo previu corretamente 99 de 116 partidas
- Precisão de 85% no torneio
- Acertou que Jannik Sinner venceria todas as suas partidas, prevendo corretamente o campeão do Grand Slam
Esse teste demonstrou o potencial real dos algoritmos de machine learning para prever resultados de tênis em torneios de alto nível.
Amplie Seus Horizontes com Machine Learning
Os resultados obtidos neste estudo mostram o enorme potencial do machine learning no mundo esportivo. Com 85% de precisão na previsão do Australian Open, ficou claro que estas técnicas podem fornecer insights valiosos não apenas para fãs de tênis, mas também para analistas esportivos, treinadores e até apostadores.
A combinação de dados históricos detalhados com algoritmos avançados como XGBoost abre caminho para análises cada vez mais sofisticadas. Que tal explorar estas técnicas em outros esportes ou aprofundar-se nos fundamentos matemáticos por trás delas?
Está animado com as possibilidades? Então não perca tempo! Explore cursos online sobre ciência de dados, experimente criar seus próprios modelos preditivos e quem sabe você não acaba prevendo o próximo campeão de Wimbledon antes de todos!
Perguntas Frequentes
Assista ao vídeo original
Este artigo foi baseado no vídeo abaixo. Se preferir, você pode assistir ao conteúdo original:
🔗 Veja também
- Direitos Autorais no Suno AI: Guia Completo Para Utilizar Músicas Geradas por IA de Forma Legal
- ChatGPT na Medicina: 6 Prompts Poderosos para Médicos e Residentes Aprimorarem sua Prática Clínica
- Como Usar o Claude Code para Construir uma Equipe de IA que Trabalha para Você
- 13 Hacks Poderosos do ChatGPT 4.0 para Criar Designs de Camisetas que Vendem
- Como Encontrar Passagens Aéreas Baratas com o ChatGPT


