
O mundo da inteligência artificial está evoluindo rapidamente, e uma das formas mais eficientes de aproveitar seu potencial é através da construção de workflows automatizados. Neste artigo, vamos explorar três workflows simples que você pode criar no n8n para impulsionar sua produtividade e aprender na prática como utilizar esta poderosa ferramenta de automação.
Se você está começando sua jornada com IA ou busca expandir suas habilidades existentes, estes workflows oferecem um excelente ponto de partida. O melhor de tudo? Vamos guiá-lo por cada etapa, incluindo a configuração de todas as credenciais necessárias e as integrações com diferentes serviços.
Entendendo os Três Workflows que Iremos Construir
💡 Dica: Pra testar ChatGPT em português sem cadastro, abra a demo grátis em /talk.php — 5 mensagens em GPT-4o-mini, sem cartão.
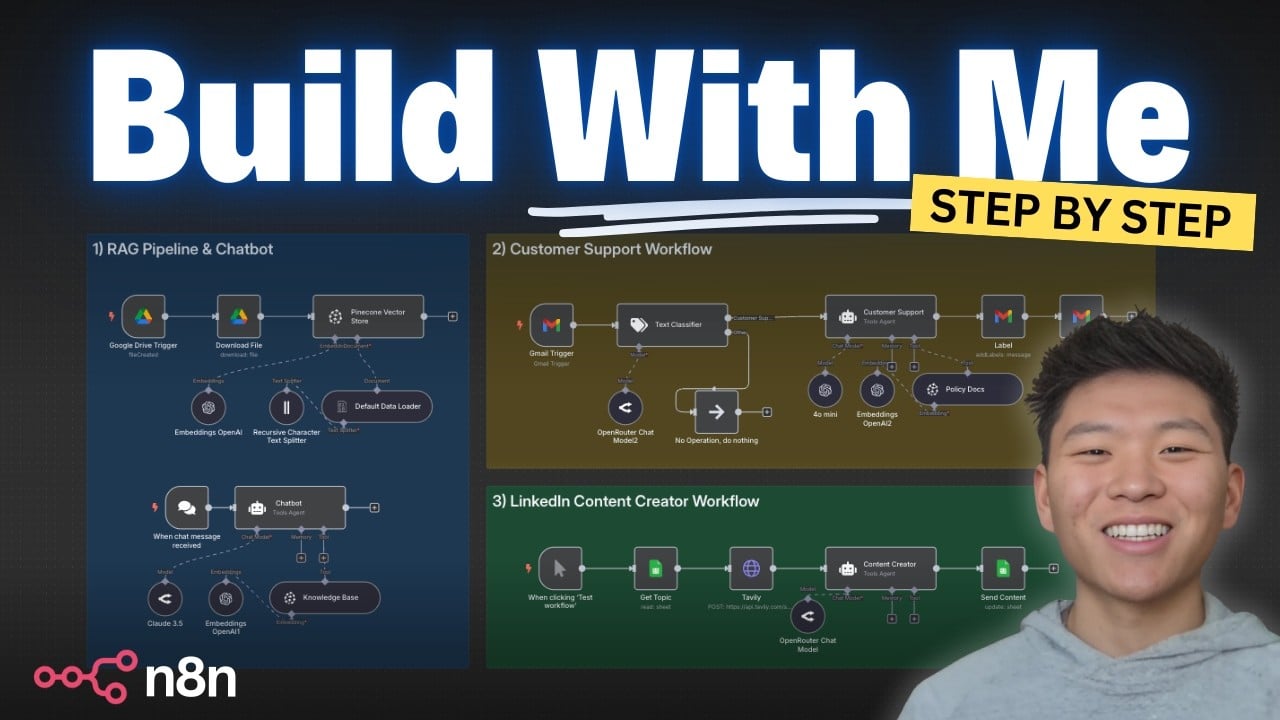
Antes de mergulharmos nos detalhes de implementação, vamos conhecer rapidamente os três workflows que vamos construir:
- Pipeline RAG e Chatbot – Utilizaremos Pinecone como banco de dados vetorial, Google Drive, Google Docs e Open Router para acessar diversos modelos de IA.
- Workflow de Suporte ao Cliente – Aproveitando o banco de dados Pinecone do primeiro workflow, conectaremos ao Gmail e utilizaremos um agente de IA do n8n junto com o Open Router.
- Criação de Conteúdo para LinkedIn – Utilizaremos um agente n8n, Open Router, Tavily para pesquisas na web e Google Sheets para armazenar e processar ideias de conteúdo.
Ao final deste guia, você terá não apenas os workflows funcionando, mas também uma base sólida para continuar aprendendo sobre o n8n. Você terá configurado diversas credenciais e entenderá como conectar diferentes serviços – uma das partes mais desafiadoras sendo a integração com o Google, que exploraremos detalhadamente.
Workflow 1: Construindo um Pipeline RAG e Chatbot
O que é RAG e Como Funcionam os Bancos de Dados Vetoriais
Antes de construir nosso primeiro workflow, vamos entender alguns conceitos fundamentais. RAG significa Retrieval Augmented Generation (Geração Aumentada por Recuperação). Em termos simples, quando perguntamos algo a um chatbot RAG e ele não sabe a resposta, ele pesquisa em uma base de conhecimento, encontra a informação relevante e então responde com base nesses dados.
Um banco de dados vetorial é um componente crucial desse sistema. Enquanto gráficos tradicionais operam em duas dimensões (X e Y), um banco de dados vetorial funciona em múltiplas dimensões. Cada “ponto” ou vetor é posicionado com base no significado semântico das palavras ou frases que representa. Por exemplo, palavras como “lobo”, “cachorro” e “gato” ficariam próximas entre si por serem animais, enquanto “maçã” e “banana” estariam em outra região por serem frutas.
Quando fazemos uma consulta, ela é transformada em um vetor e posicionada nesse espaço multidimensional. O sistema então recupera os vetores mais próximos, que contêm as informações mais relevantes para responder à pergunta.
Configurando o Workflow no n8n
Vamos começar configurando nosso primeiro workflow:
- Configurar o gatilho do Google Drive: Este será o início do nosso workflow, monitorando uma pasta específica para novos arquivos.
- Configurar as credenciais do Google Cloud: Criaremos um projeto no Google Cloud, habilitaremos a API do Google Drive e configuraremos a tela de consentimento OAuth.
- Conectar o Pinecone: Configuraremos o banco de dados vetorial para armazenar nossos documentos processados.
- Adicionar modelos de embeddings: Usaremos o modelo Text Embedding 3 Small da OpenAI para transformar texto em vetores.
- Configurar o divisor de texto: Dividiremos documentos grandes em chunks menores para processamento eficiente.
- Adicionar o chatbot RAG: Criaremos um agente de IA que usará nossa base de conhecimento para responder perguntas.
Criando o Projeto no Google Cloud
Para configurar as credenciais do Google Drive:
- Acesse o Google Cloud e crie um novo projeto.
- Vá para “APIs e Serviços” e habilite a API do Google Drive.
- Configure a tela de consentimento OAuth, escolhendo o tipo “Externo” para contas pessoais.
- Adicione-se como usuário de teste.
- Crie um novo cliente OAuth como “Aplicativo Web” e adicione o URI de redirecionamento fornecido pelo n8n.
- Copie o ID do cliente e o segredo para usar no n8n.
Após conectar sua conta do Google Drive no n8n, crie uma pasta chamada “FAQ” e faça upload de um documento com políticas e perguntas frequentes. Configuraremos o workflow para monitorar novos arquivos nesta pasta.
Configurando o Pinecone como Banco de Dados Vetorial
Para configurar o Pinecone:
- Crie uma conta no Pinecone.io e inicie a configuração de um novo índice.
- Escolha o modelo de embeddings “Text Embedding 3 Small” da OpenAI.
- Mantenha a configuração como serverless, usando AWS como provedor de nuvem.
- Após criar o índice, gere uma nova chave de API para usar no n8n.
No n8n, adicione um nó “Pinecone Vector Store” após o download do arquivo do Google Drive. Configure-o para adicionar documentos ao banco de dados, usando a chave API que você acabou de criar e especificando um namespace chamado “FAQ” para organizar seus dados.
Adicionando o Modelo de Embeddings e o Divisor de Texto
Conecte um modelo de embeddings da OpenAI ao seu nó do Pinecone. Certifique-se de usar o mesmo modelo que você escolheu ao criar o índice no Pinecone (Text Embedding 3 Small).
Em seguida, adicione um divisor de texto recursivo para dividir seu documento em chunks. Configure-o com um tamanho de chunk de 1000 caracteres para manter um bom equilíbrio entre contexto e eficiência.
Configurando o Chatbot RAG
Para finalizar o primeiro workflow:
- Adicione um nó “AI Agent” ao seu workflow.
- Conecte um gatilho de chat para permitir interações com o agente.
- Adicione um modelo de chat do Open Router (por exemplo, Claude 3.5 Sonnet).
- Configure uma ferramenta Pinecone Vector Store para o agente, apontando para o namespace “FAQ” que criamos anteriormente.
- Adicione o mesmo modelo de embeddings (Text Embedding 3 Small) à ferramenta Pinecone.
Agora seu chatbot RAG está pronto! Ele pode acessar as informações armazenadas no seu banco de dados vetorial Pinecone para fornecer respostas precisas baseadas nos documentos que você carregou.
Workflow 2: Suporte ao Cliente Automatizado
Nosso segundo workflow amplia o primeiro, utilizando o banco de dados Pinecone que já configuramos para responder a e-mails de suporte ao cliente. Isso mostra como você pode reutilizar componentes entre workflows para maior eficiência.
Configurando a Integração com o Gmail
Para configurar a integração com o Gmail:
- Adicione um nó de gatilho do Gmail no n8n.
- Configure as credenciais do Gmail usando as mesmas etapas que usamos para o Google Drive.
- Configure o gatilho para monitorar e-mails com rótulos específicos ou critérios de pesquisa.
Criando o Agente de Resposta Automática
Configure um agente n8n para analisar e-mails recebidos:
- Conecte o agente ao gatilho do Gmail.
- Adicione o modelo de chat do Open Router.
- Conecte a ferramenta Pinecone Vector Store, apontando para o namespace FAQ.
- Configure instruções para o agente sobre como responder a e-mails de suporte com base nas informações do banco de dados.
Adicione um nó de saída do Gmail para enviar as respostas geradas pelo agente de volta aos clientes, completando assim o ciclo de suporte automatizado.
Workflow 3: Criação de Conteúdo para LinkedIn
Nosso terceiro workflow se concentra na criação automatizada de conteúdo para LinkedIn, combinando pesquisa na web e armazenamento em planilhas.
Configurando o Tavily para Pesquisa na Web
Tavily é uma ferramenta que permite que seu agente de IA pesquise na web em tempo real:
- Crie uma conta no Tavily e obtenha sua chave API.
- No n8n, adicione a credencial do Tavily usando a chave API.
- Configure uma ferramenta de pesquisa Tavily para o seu agente.
Integrando com o Google Sheets
Para armazenar e organizar ideias de conteúdo:
- Crie uma planilha no Google Sheets com colunas para ideias de conteúdo, status, conteúdo gerado, etc.
- No n8n, adicione nós de entrada e saída do Google Sheets.
- Configure-os para ler ideias da planilha e escrever o conteúdo gerado de volta para ela.
Criando o Pipeline de Conteúdo
Configure seu agente para gerar conteúdo de alta qualidade:
- Conecte o agente às entradas do Google Sheets.
- Adicione o modelo de chat do Open Router.
- Configure a ferramenta Tavily para pesquisar informações relevantes sobre os tópicos.
- Forneça instruções detalhadas sobre formatos de conteúdo do LinkedIn e tom de voz desejado.
- Conecte a saída do agente ao nó de saída do Google Sheets.
Este workflow pode ser programado para executar regularmente, garantindo um fluxo constante de conteúdo para sua presença no LinkedIn.
Potencialize Seus Processos com Automação Inteligente
Os três workflows que construímos neste guia são apenas o começo do que é possível com o n8n e outras ferramentas de automação de IA. Estas não são soluções estáticas – elas podem e devem evoluir conforme seus requisitos mudam e novos modelos de IA são lançados.
O verdadeiro poder desses workflows está na sua capacidade de personalização. Você pode adaptar cada componente para atender às suas necessidades específicas, seja ajustando as instruções dos agentes, integrando serviços adicionais ou refinando os prompts para obter resultados melhores.
Está pronto para levar sua automação ao próximo nível? Comece implementando esses workflows hoje mesmo e experimente o poder da IA trabalhando para você. Não se esqueça de monitorar o desempenho e fazer ajustes conforme necessário. A jornada de aprendizado é contínua, e cada iteração trará melhorias significativas aos seus processos automatizados.
Perguntas Frequentes
Assista ao vídeo original
Este artigo foi baseado no vídeo abaixo. Se preferir, você pode assistir ao conteúdo original:
🔗 Veja também
- Como Usar o Claude Code para Construir uma Equipe de IA que Trabalha para Você
- Codex: Como Usar a Ferramenta de IA para Desenvolvimento Web Mesmo Sem Conhecimento Técnico
- O Prompt que Revoluciona a IA: Como o ChatGPT Pode Ser seu Consultor Pessoal de R$500/hora
- Como Criar um Agente de IA que Escreve Exatamente como Você: Guia Completo para 2025
- Direitos Autorais no Suno AI: Guia Completo Para Utilizar Músicas Geradas por IA de Forma Legal


